Confidence Interval of a Mean#
Introduction#
In biostatistics, we often estimate characteristics of a larger population from a smaller sample. But how confident are we in those estimates? This chapter introduces the concept of confidence intervals — a powerful tool that tells us how reliable our estimates are likely to be.
Confidence intervals are like a range of plausible values, instead of just a single number. We’ll learn how to calculate and interpret these intervals for the most important statistic in biostatistics: the mean.
By the end of this chapter, we’ll understand how confidence intervals work, how to use them to make stronger conclusions about our data, and how to avoid common misunderstandings. Whether we’re new to statistics or just looking for a refresher, this chapter will give us the confidence we need to tackle this essential concept.
The t-distribution#
To determine the width of the confidence interval of a mean, we utilize a constant called the critical value from the t-distribution, or the critical t-value denoted as \(t^*\). The t-distribution is similar to the standard normal distribution but is used when the population standard deviation is unknown and estimated from the sample. The choice of \(t^*\) depends on the desired confidence level and the degrees of freedom (\(\text{df}\)). In general, \(\text{df}\) equals the number of data points \(n\) minus the number of parameters being estimated, e.g., \(\text{df} = n - 1\) for the mean.
Origin of the t-distribution#
The t-distribution (or Student distribution) was developed by William Sealy Gosset, a chemist working for the Guinness brewery in the early 20th century. He published his work under the pseudonym “Student” due to company restrictions. The distribution arose from Gosset’s need to make inferences about the mean of a normally distributed population when the sample size was small and the population standard deviation was unknown. The t-distribution is similar to the standard normal distribution (z-distribution) but has heavier tails, especially with smaller sample sizes. As the sample size increases, the t-distribution approaches the z-distribution.
Using scipy.stats to obtain critical t-values#
The scipy.stats module in Python provides a convenient way to work with the t-distribution and obtain critical t-values. For a two-tailed confidence interval, the expression \(1 - \alpha/2\) is used to find the critical t-value, with \(\alpha\) the signifcance level, also called the complement of the confidence level.
from scipy.stats import t
# Define the desired confidence level (e.g., 95%)
confidence_level = 0.95
# Calculate alpha (for two-tailed test)
alpha = 1 - confidence_level
# Define the degrees of freedom (e.g., sample size - 1)
df = 27
# Calculate the critical t-value (two-tailed)
#t_critical = t.ppf(1 - alpha/2, df) # ppf is the percent point function (inverse of CDF)
t_critical = t(df=df).ppf(q=1 - alpha/2) # ppf is the percent point function (inverse of CDF)
print(f"The two-tailed critical t-value for a {100*confidence_level}% CI \
with {df} degrees of freedom is {t_critical:.4f}")
The two-tailed critical t-value for a 95.0% CI with 27 degrees of freedom is 2.0518
In Microsoft Excel, we can use
T.INV.2T(1-0.95, 27).
To access a wider range of t-values for various confidence levels and degrees of freedom, we can generate the following table.
import pandas as pd
# Confidence levels
confidence_levels = [0.80, 0.90, 0.95, 0.975, 0.99] # conf_lev = 1 - alpha
# Degrees of freedom
df_values = list(range(1, 11)) + list(range(50, 251, 50))
# Create an empty dictionary to store t-values
data = {}
# Calculate t-values and populate dictionary
for df in df_values:
t_values = [t.ppf((1 + conf_lev) / 2, df) for conf_lev in confidence_levels]
data[df] = t_values
# Create a DataFrame from the dictionary
df = pd.DataFrame(data, index=confidence_levels)
# Format the table
df.index.name = '1-α'
df.columns.name = 'df'
# Print the table
print("Two-tailed critical values of the t-distribution for various degrees of freedom (columns) and confidence levels (rows)")
print("===========================================================================================================")
print(df.round(3).to_markdown(numalign='left', stralign='left'))
Two-tailed critical values of the t-distribution for various degrees of freedom (columns) and confidence levels (rows)
===========================================================================================================
| 1-α | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 50 | 100 | 150 | 200 | 250 |
|:------|:-------|:------|:------|:------|:------|:------|:------|:------|:------|:------|:------|:------|:------|:------|:------|
| 0.8 | 3.078 | 1.886 | 1.638 | 1.533 | 1.476 | 1.44 | 1.415 | 1.397 | 1.383 | 1.372 | 1.299 | 1.29 | 1.287 | 1.286 | 1.285 |
| 0.9 | 6.314 | 2.92 | 2.353 | 2.132 | 2.015 | 1.943 | 1.895 | 1.86 | 1.833 | 1.812 | 1.676 | 1.66 | 1.655 | 1.653 | 1.651 |
| 0.95 | 12.706 | 4.303 | 3.182 | 2.776 | 2.571 | 2.447 | 2.365 | 2.306 | 2.262 | 2.228 | 2.009 | 1.984 | 1.976 | 1.972 | 1.969 |
| 0.975 | 25.452 | 6.205 | 4.177 | 3.495 | 3.163 | 2.969 | 2.841 | 2.752 | 2.685 | 2.634 | 2.311 | 2.276 | 2.264 | 2.258 | 2.255 |
| 0.99 | 63.657 | 9.925 | 5.841 | 4.604 | 4.032 | 3.707 | 3.499 | 3.355 | 3.25 | 3.169 | 2.678 | 2.626 | 2.609 | 2.601 | 2.596 |
Sign of the critical t-value#
The t-distribution is symmetrical around zero, meaning that the probability density is the same for positive and negative t-values with the same absolute value.
In a one-tailed test, we’re interested in whether the population mean is significantly greater than or less than a specific value.
Left-tailed test: the critical t-value will be negative because we’re looking for evidence in the left tail of the distribution.
Right-tailed test: the critical t-value will be positive because we’re looking for evidence in the right tail of the distribution.
In a two-tailed test or when calculating a confidence interval, we consider both tails of the distribution.
We’ll typically get two critical t-values: one positive and one negative, corresponding to the upper and lower bounds of the confidence interval or the rejection regions in a two-tailed test.
# Parameters
df = 11 # Degrees of freedom (n - 1)
confidence_level = 0.95
# Calculate critical t-values
alpha = 1 - confidence_level
t_critical = t.ppf(1 - alpha / 2, df)
# Or we can calculate critical t-values using ppf directly
# note that 0.975 - 0.025 = 0.95
t_critical_lower = t.ppf(0.025, df) # Lower critical value at q = 0.025
t_critical_upper = t.ppf(0.975, df) # Upper critical value at q = 0.975
print(f"For a {100*confidence_level}% confidence interval with {df} degrees of freedom:")
print(f"The lower critical t-value is {t_critical_lower:.1f} \
({100*(1-confidence_level)/2:.1f}% of the area under the curve is to the left of this value)")
print(f"The upper critical t-value is {t_critical_upper:.1f} \
({100*(1-confidence_level)/2:.1f}% of the area under the curve is to the right of this value)")
For a 95.0% confidence interval with 11 degrees of freedom:
The lower critical t-value is -2.2 (2.5% of the area under the curve is to the left of this value)
The upper critical t-value is 2.2 (2.5% of the area under the curve is to the right of this value)
Visualizing the t-distribution#
To gain a deeper understanding of this distribution, let’s visualize its shape and key properties.
The plot generated below depicts the Probability Density Function (PDF) of the t-distribution for a specific degrees of freedom (df) value. This curve represents the likelihood of different t-values occurring under this distribution.
import numpy as np
import matplotlib.pyplot as plt
# Parameters
df = 11 # Degrees of freedom (n - 1)
confidence_level = 0.95
# Calculate critical t-values
alpha = 1 - confidence_level
t_critical = t.ppf(1 - alpha / 2, df)
# Or we can calculate critical t-values using ppf directly
# note that 0.975 - 0.025 = 0.95
t_critical_lower = t.ppf(0.025, df) # Lower critical value at q = 0.025
t_critical_upper = t.ppf(0.975, df) # Upper critical value at q = 0.975
# Generate x values for the plot
# x = np.linspace(-4, 4, 100) # Range from -4 to 4 standard deviations
# We could also use the PPF, e.g., if the model is predefined
x=np.linspace(
t(df=df).ppf(q=.001), # Percent Point Function
t(df=df).ppf(q=.999),
num=200)
# Calculate t-distribution PDF values
y = t.pdf(x, df)
# Create the plot
# plt.figure(figsize=(4, 3))
plt.plot(x, y, 'k', label=f"t-distribution (df={df})")
# Shade confidence interval areas
# plt.fill_between(x, y, where=((x < -t_critical) | (x > t_critical)), color='mediumorchid',)
plt.fill_between(
x, y,
where=((x < t_critical_lower) | (x > t_critical_upper)),
color='mediumorchid',)
# Add labels and title
plt.xlabel('t-value')
plt.ylabel('Probability Density')
plt.title(f"t-distribution with {df} degrees of freedom\
\n({100*confidence_level}% confidence interval)");
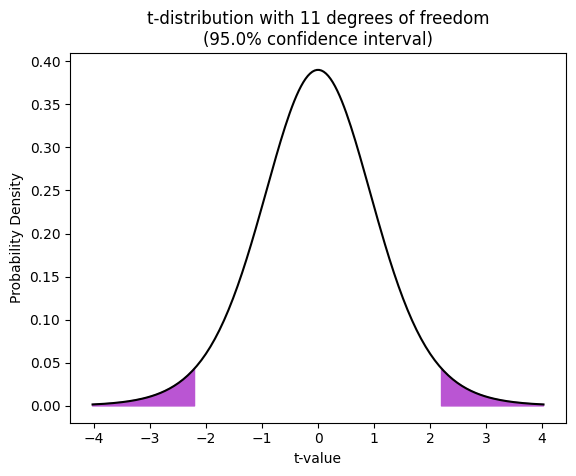
Notice that:
Bell-shaped: similar to the standard normal distribution, the t-distribution is symmetrical and bell-shaped.
Heavier tails: the tails of the t-distribution are thicker than those of the standard normal distribution, especially for smaller degrees of freedom. This reflects the increased uncertainty associated with smaller sample sizes.
Approaches normal distribution: as the degrees of freedom increase (i.e., with larger sample sizes), the t-distribution approaches the standard normal distribution.
The shaded areas in the plot highlight the 95% confidence interval. This means that if we were to repeatedly sample from the population and calculate confidence intervals using the t-distribution, 95% of those intervals would contain the true population mean. The critical t-values that define the boundaries of this interval, i.e., 2.5% probability in each tail, are calculated using the t.ppf function, as discussed in the previous chapters.
Let’s now plot multiple t-distributions with varying degrees of freedom on the same graph, to illustrate how the shape changes as the sample size increases.
import seaborn as sns
sns.set_palette("magma_r")
# Degrees of freedom
df_values = [1, 2, 5, 10, 25]
# Generate x values for the plot
x = np.linspace(-5, 5, 200)
# Create the plot
# plt.figure(figsize=(5, 4))
for df in df_values:
# Calculate t-distribution PDF values
y = t.pdf(x, df)
# Plot the t-distribution
plt.plot(x, y, label=f'df = {df}')
# Add labels and title
plt.xlabel('t-value')
plt.ylabel('Probability Density')
plt.title('t-distributions with varying degrees of freedom')
plt.legend();
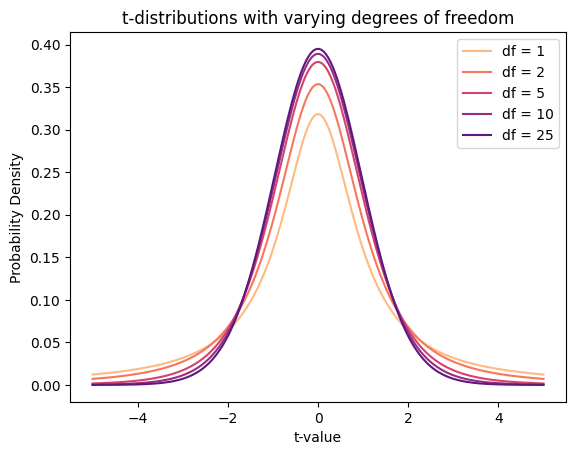
The plot illustrates the following key characteristics of t-distributions:
Bell-shaped: all t-distributions are bell-shaped and symmetric around zero.
Heavier tails with smaller df: the t-distributions with smaller degrees of freedom (e.g., \(\text{df} = 1\)) have heavier tails compared to those with larger degrees of freedom (e.g., \(\text{df} = 25\)). This indicates a higher probability of obtaining extreme values (far from the mean) when the sample size is small.
Approaching the Standard Normal#
As the degrees of freedom increase, the t-distribution becomes more and more similar to the standard normal distribution (z-distribution). This is evident in the plot, where the curve for \(\text{df} = 25\) closely resembles the standard normal curve.
from scipy.stats import norm
# Set up parameters
df = 25 # Degrees of freedom for t-distribution
x = np.linspace(-4, 4, 400) # Range of x values
# Calculate PDF values
t_pdf = t.pdf(x, df)
norm_pdf = norm.pdf(x)
# Plot
plt.plot(x, t_pdf, lw=3, ls='--', color='blue', label=f"t-distribution (df={df})")
plt.plot(x, norm_pdf, lw=3, label='Standard Normal (Gaussian)')
plt.title(
'Comparison of t-distribution and Standard Normal PDFs',
fontsize=14)
plt.xlabel('x')
plt.ylabel('Probability density')
plt.legend()
plt.grid(axis='y', alpha=0.75)
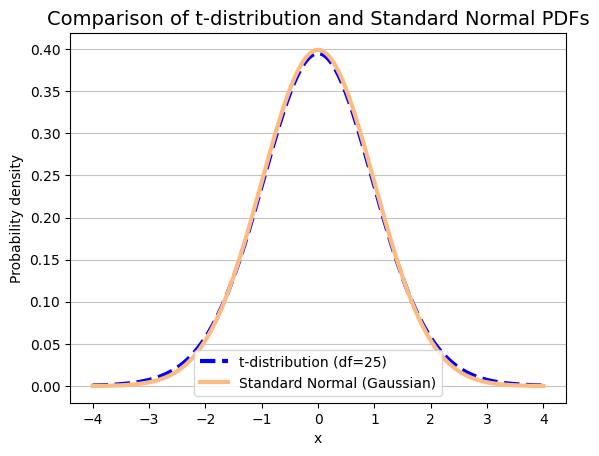
This convergence is a consequence of the Central Limit Theorem (CLT), which states that the distribution of sample means approaches a normal distribution as the sample size increases, regardless of the shape of the original population distribution. Since degrees of freedom are directly related to sample size (\(\text{df} = n - 1\)), as \(\text{df}\) increases, the sample size also increases, and the t-distribution becomes increasingly similar to the standard normal distribution.
In principle, when the sample size is large (typically \(n > 30\)), the t-distribution and the standard normal distribution are very close. In this case, we can use either the z-score or the t-value for the CI calculations, and the results will be virtually identical.
Calculating the confidence interval of a mean#
The most common method of computing the confidence interval (CI) of a mean assumes that the data are sampled from a population that follows a normal distribution. The CI is centered around the sample mean \(m\). To calculate its width, we need to consider the standard deviation \(s\), the number of values in the sample \(n\), and the desired degree of confidence (typically 95%).
The t-statistic#
While we can use the t-distribution to calculate confidence intervals and test hypotheses about the population mean, it’s important to distinguish between the t-statistic (calculated from the sample data) and the critical t-value (obtained from the t-distribution as shown above).
Suppose we have a population that is normally distributed, with known parameters \(\mu\) (mean) and \(\sigma\) (standard deviation). By taking multiple random samples of size \(n\) from this population, we can compute the sample mean (\(m\)) and sample standard deviation (\(s\)) for each. Then, for each sample, we can calculate the t-statistic (\(t\)):
The t-statistic tells us how extreme the sample mean is compared to the hypothesized population mean, under the assumption that the null hypothesis is true (i.e., the true population mean is equal to the hypothesized value).
A larger absolute value of \(t\) indicates a more significant difference between the sample mean and the hypothesized population mean.
The sign of \(t\) indicates whether the sample mean is larger (+) or smaller (-) than the hypothesized population mean.
For example, suppose we want to test whether a new drug has an effect on blood pressure. We collect a sample of 30 patients and measure their blood pressure after taking the drug. The sample mean (m) is 120 mmHg, and the sample standard deviation (s) is 15 mmHg. Our hypothesize that the population mean blood pressure with the drug (\(\mu\)) is 130 mmHg.
t_stat = (120 - 130) / (15 / np.sqrt(30))
print(f"The t-statistic in this sample = {t_stat:.3f}")
The t-statistic in this sample = -3.651
The result indicates that the sample mean is 3.651 standard errors lower than the hypothesized population mean of 130 mmHg.
Once we’ve calculated the t-statistic, we can use the t-distribution to determine:
P-value: the probability of observing a t-statistic as extreme as or more extreme than the one calculated, assuming the null hypothesis is true. A smaller p-value provides stronger evidence against the null hypothesis.
Critical t-value: the t-value that corresponds to our chosen significance level (alpha) and degrees of freedom. If our calculated t-statistic is more extreme than the critical t-value, we reject the null hypothesis.
The flip#
For any individual sample, we know the specific values for the sample mean, standard deviation, and size. The population mean, though, remains hidden. Our goal is to estimate this population mean while quantifying our level of uncertainty. To achieve this, we can calculate a confidence interval (CI) as follows:
To estimate the population mean with a specified level of confidence, we can employ the t-distribution and follow this procedure:
Calculate the sample mean (\(m\)) and sample standard deviation (\(s\))
Determine the degrees of freedom (\(df = n - 1\))
Choose a confidence level (e.g., 95%)
Find the critical t-value (\(t^*\))
Calculate the margin of error as \(W = \frac{t^* \times s}{\sqrt{n}}\)
Construct the confidence interval, as \(\text{CI} = m \pm W\)
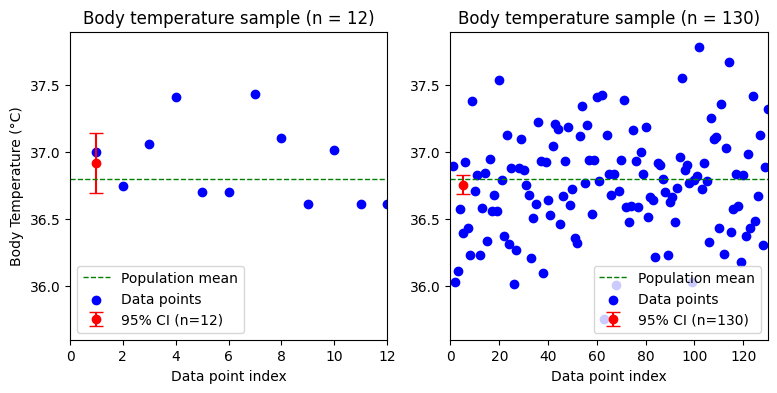
Example of body temperatures#
To illustrate the effect of sample size on the confidence interval, we will simulate two datasets of body temperatures with the same population mean and SD, but with different sample sizes (n=12 and n=130). We will assume the body temperatures are normally distributed with a population mean of 36.8 and a standard deviation of 0.4. We will then calculate and visualize the 95% confidence intervals for each sample using the critical z-values, supposing we know the population standard deviation. (The difference between critical t- and z-values is discussed just after that, for now just focus on the confidence intervals.)
# Set random seed for reproducibility
np.random.seed(42)
# Population parameters
pop_mean = 36.8
pop_sd = 0.4
# Sample sizes
n1 = 12
n2 = 130
# Generate samples
sample1 = np.random.normal(pop_mean, pop_sd, n1)
sample2 = np.random.normal(pop_mean, pop_sd, n2)
# Calculate sample means and standard errors
sample_mean1 = np.mean(sample1)
sample_mean2 = np.mean(sample2)
sem1 = pop_sd / np.sqrt(n1)
sem2 = pop_sd / np.sqrt(n2)
# Calculate z-critical value for 95% CI (since pop std is known)
z_crit = norm.ppf(0.975) # ppf gives us z score for 97.5%
# Calculate margin of error
margin_error1 = z_crit * sem1
margin_error2 = z_crit * sem2
# Calculate confidence intervals
ci_lower1 = sample_mean1 - margin_error1
ci_upper1 = sample_mean1 + margin_error1
ci_lower2 = sample_mean2 - margin_error2
ci_upper2 = sample_mean2 + margin_error2
# Create point plots with confidence intervals
plt.figure(figsize=(9, 4))
plt.subplot(121) # 1 row, 2 columns, subplot 1
plt.errorbar(
[1], [sample_mean1],
yerr=margin_error1,
fmt='ro', capsize=5,
label=f'95% CI (n={n1})')
plt.axhline(
pop_mean,
color='g', linestyle='dashed', linewidth=1,
label='Population mean')
plt.scatter(
range(1, n1 + 1), sample1,
color='b',
label='Data points')
plt.xlabel('Data point index')
plt.xlim(0,12)
plt.ylabel('Body Temperature (°C)')
plt.ylim(35.6, 37.9)
plt.title(f'Body temperature sample (n = {n1})')
plt.legend()
plt.subplot(122) # 1 row, 2 columns, subplot 2
plt.errorbar(
[5], [sample_mean2],
yerr=margin_error2,
fmt='ro', capsize=5,
label=f'95% CI (n={n2})')
plt.axhline(
pop_mean,
color='g', linestyle='dashed', linewidth=1,
label='Population mean')
plt.scatter(
range(1, n2 + 1), sample2,
color='b',
label='Data points')
plt.xlabel('Data point index')
plt.xlim(0,130)
plt.title(f'Body temperature sample (n = {n2})')
plt.ylim(35.6, 37.9)
plt.legend();
# Print the results
print(f"Critical z-value = {z_crit:.6f}\n")
print(f"Sample size n = {n1}, with known population SD of {pop_sd}:")
print(f" Sample mean: {sample_mean1:.4f}")
print(f" SE (sigma / sqrt(n)): {sem1:.5f}")
print(f" Margin of error: {margin_error1:.5f}")
print(f" 95% confidence interval: ({ci_lower1:.4f}, {ci_upper1:.4f})")
print(f"\nSample size n = {n2}, with known population SD of {pop_sd}:")
print(f" Sample mean: {sample_mean2:.4f}")
print(f" SE (sigma / sqrt(n)): {sem2:.5f}")
print(f" Margin of error: {margin_error2:.5f}")
print(f" 95% confidence interval: ({ci_lower2:.4f}, {ci_upper2:.4f})")
Critical z-value = 1.959964
Sample size n = 12, with known population SD of 0.4:
Sample mean: 36.9184
SE (sigma / sqrt(n)): 0.11547
Margin of error: 0.22632
95% confidence interval: (36.6921, 37.1447)
Sample size n = 130, with known population SD of 0.4:
Sample mean: 36.7576
SE (sigma / sqrt(n)): 0.03508
Margin of error: 0.06876
95% confidence interval: (36.6888, 36.8264)
As the number of observations in a sample increases, the sample statistics tend to converge towards the actual population parameters. This means that the t-distribution, used when the population standard deviation is unknown, closely resembles the z-distribution (standard normal distribution) in larger samples. Therefore, for samples of 50 or more observations, the choice between using the t-distribution or z-distribution for calculating confidence intervals or P values becomes less critical, as the results will be practically identical. In some later models, we may see references to either t-statistics or z-statistics, but remember that this distinction is mainly significant for smaller sample sizes.
Critical z- vs. t-values#
We can use the critical z-value instead of the critical t-value when calculating the margin of error in certain situations, but it’s important to understand the conditions under which this is appropriate.
When to use the z-value:
The population standard deviation (\(\sigma\)) is known: if we have access to the true population standard deviation, we can directly use the z-distribution (standard normal distribution) to calculate the critical value.
The sample size is large (typically n > 30): the Central Limit Theorem states that the distribution of sample means approaches a normal distribution as the sample size increases. For large samples, the t-distribution closely approximates the z-distribution, making the z-value a valid substitute.
When to use the t-value:
The population standard deviation (\(\sigma\)) is unknown: this is the most common scenario in real-world applications. When we don’t know the population standard deviation, we estimate it from the sample data (using the sample standard deviation, \(s\)). The t-distribution accounts for the additional uncertainty introduced by this estimation.
The sample size is small (typically n < 30): with small sample sizes, the t-distribution has heavier tails than the z-distribution, reflecting the greater variability in sample means. Using the t-distribution provides a more accurate confidence interval in this case.
Using the z-value when the t-value is appropriate can lead to narrower confidence intervals that may not accurately capture the true population parameter. The t-distribution provides a more conservative estimate in these cases. But the distinction between the t-distribution and z-distribution becomes less critical as the sample size increases. For very large samples (n > 100), the difference is negligible, and either distribution can be used.
For example, suppose we have a sample of 12 measurements with a sample mean (\(m\)) of 36.9184 and a sample standard deviation (\(s\)) of 0.2977. We want a 95% confidence interval. If we know the population standard deviation (here \(\sigma=0.4\)), we can use the z-value (1.959964 for a 95% CI) to calculate the margin of error, as we did just above. If we don’t know the population standard deviation, we should use the t-value (2.200985 for a 95% CI with 11 degrees of freedom) to calculate the margin of error, as demonstrated below.
# Population parameters (known)
pop_mean = 36.8
pop_sd = 0.4
# Sample sizes
n1 = 12
n2 = 130
# Generate samples (for demonstration purposes)
np.random.seed(42) # for reproducibility
sample1 = np.random.normal(pop_mean, pop_sd, n1)
sample2 = np.random.normal(pop_mean, pop_sd, n2)
# Calculate sample means
sample_mean1 = np.mean(sample1)
sample_mean2 = np.mean(sample2)
# Confidence level
confidence_level = 0.95
alpha = 1 - confidence_level
# Calculate critical t-values
t_critical1 = t.ppf(1 - alpha/2, n1-1)
t_critical2 = t.ppf(1 - alpha/2, n2-1)
# Calculate sample standard deviations
sample_sd1 = np.std(sample1, ddof=1)
sample_sd2 = np.std(sample2, ddof=1)
# Calculate standard error of the mean
sem1 = sample_sd1 / np.sqrt(n1)
sem2 = sample_sd2 / np.sqrt(n2)
# Calculate margin of error
margin_error1 = t_critical1 * sem1
margin_error2 = t_critical2 * sem2
# Calculate confidence intervals
ci_lower1 = sample_mean1 - margin_error1
ci_upper1 = sample_mean1 + margin_error1
ci_lower2 = sample_mean2 - margin_error2
ci_upper2 = sample_mean2 + margin_error2
# Print the results
print(f"Sample size n = {n1}, with unknown population SD:")
print(f" Critical t-value = {t_critical1:.6f}")
print(f" Sample mean: {sample_mean1:.4f}")
print(f" Sample SD: {sample_sd1:.4f}")
print(f" Sample SE: {sem1:.5f}")
print(f" Margin of error: {margin_error1:.5f}")
print(f" 95% confidence Interval: ({ci_lower1:.4f}, {ci_upper1:.4f})")
print(f"\nSample size n = {n2}, with unknown population SD:")
print(f" Critical t-value = {t_critical2:.6f}")
print(f" Sample mean: {sample_mean2:.4f}")
print(f" Sample SD: {sample_sd2:.4f}")
print(f" Sample SE: {sem2:.5f}")
print(f" Margin of error: {margin_error2:.5f}")
print(f" 95% confidence Interval: ({ci_lower2:.4f}, {ci_upper2:.4f})")
Sample size n = 12, with unknown population SD:
Critical t-value = 2.200985
Sample mean: 36.9184
Sample SD: 0.2977
Sample SE: 0.08594
Margin of error: 0.18915
95% confidence Interval: (36.7292, 37.1075)
Sample size n = 130, with unknown population SD:
Critical t-value = 1.978524
Sample mean: 36.7576
Sample SD: 0.3822
Sample SE: 0.03352
Margin of error: 0.06633
95% confidence Interval: (36.6913, 36.8239)
Python tools for confidence interval calculation#
There are several ways to directly calculate CIs in Python using various packages.
Frequentist - Normal distribution#
This frequentist method assumes that the data are sampled from a normally distributed population, and that the population standard deviation is known. This function calculates the confidence interval based on the z-score (standard normal distribution), which is appropriate under these frequentist assumptions. If we have a large sample size (n > 30), the normal distribution is often sufficient.
# Calculate 95% confidence interval (assuming known population std_dev)
confidence_level = 0.95
sample_mean = np.mean(sample2)
# Here, we would typically use the population std_dev when it is known,
# or an estimate (e.g., from previous studies)
sd2 = np.std(sample2, ddof=1)
ci1 = norm.interval(confidence_level, loc=sample_mean, scale=pop_sd)
ci2 = norm.interval(confidence_level, loc=sample_mean, scale=sd2)
print(f"95% confidence interval (known population SD): ({ci1[0]:.3f}, {ci1[1]:.3f})")
print(f"95% confidence interval (sample SD): ({ci2[0]:.3f}, {ci2[1]:.3f})")
95% confidence interval (known population SD): (35.974, 37.542)
95% confidence interval (sample SD): (36.008, 37.507)
Frequentist - Student/t-distribution#
Other frequentist methods provide a convenient way to calculate the confidence interval for a mean using the t-distribution. For example, statsmodels.stats.weightstats.DescrStatsW.tconfint_mean takes the data as input and returns the confidence interval directly. If we have a small sample size and don’t know the population standard deviation, the t-distribution is generally the most appropriate choice.
import statsmodels.api as sm
confidence_level = 0.95
# Calculate 95% confidence interval
ci = sm.stats.DescrStatsW(sample1).tconfint_mean(alpha=1-confidence_level)
print(f"95% confidence interval (t-distribution, estimated SD; DescrStatsW): \
({ci[0]:.3f}, {ci[1]:.3f})")
95% confidence interval (t-distribution, estimated SD; DescrStatsW): (36.729, 37.108)
This method is based on the confidence interval with equal areas around the median from the t-distribution, as calculated with scipy.stats.t.interval.
sem = np.std(sample1, ddof=1) / np.sqrt(len(sample1))
ci = t.interval(
confidence=confidence_level,
df=len(sample1) - 1,
loc=np.mean(sample1),
scale=sem) # here scale is SE, no SD as in normal distribution
print(f"95% confidence interval (t-distribution, estimated SD; t.interval): \
({ci[0]:.3f}, {ci[1]:.3f})")
95% confidence interval (t-distribution, estimated SD; t.interval): (36.729, 37.108)
Bayesian approach#
Bayesian methods allow us to incorporate prior beliefs or information about the parameters we’re estimating. This can be particularly useful when we have some knowledge about the data generating process or when we have limited data. They produce credible intervals, which are a more intuitive and direct interpretation of uncertainty compared to frequentist confidence intervals. A 95% credible interval means there’s a 95% probability the true parameter lies within that interval, given the data and the prior. Bayesian methods are less sensitive to small sample sizes than frequentist methods, which often rely on asymptotic assumptions that may not hold for small datasets. Bayesian statistics is a vast and complex field with dedicated Python libraries like PyMC3 and Stan.
The scipy.stats.bayes_mvs function simplifies the calculation of Bayesian credible intervals for the mean, variance, and standard deviation. It uses Jeffrey’s prior, a non-informative prior that doesn’t introduce strong assumptions about the parameter values. This can be a good starting point for Bayesian analysis when you have limited prior knowledge.
Note: for samples of size smaller than 1000, the function resorts to a frequentist approach. It calculates the sample mean and standard deviation, and then uses the t-distribution with n-1 degrees of freedom to determine the confidence interval.
from scipy.stats import bayes_mvs
# Calculate 95% Bayesian confidence interval for the mean
result = bayes_mvs(sample1, alpha=0.95)
ci_lower, ci_upper = result[0][1] # Extract lower and upper bounds from the result object
print(f"95% confidence interval in the dataset with n={n1}: ({ci_lower:.3f}, {ci_upper:.3f})")
95% confidence interval in the dataset with n=12: (36.729, 37.108)
# Calculate 95% Bayesian confidence interval for the mean
result = bayes_mvs(sample2, alpha=0.95)
ci_lower, ci_upper = result[0][1] # Extract lower and upper bounds from the result object
print(f"95% confidence interval in the dataset with n={n2}: ({ci_lower:.3f}, {ci_upper:.3f})")
95% confidence interval in the dataset with n=130: (36.691, 36.824)
Non-parametric approach#
Resampling#
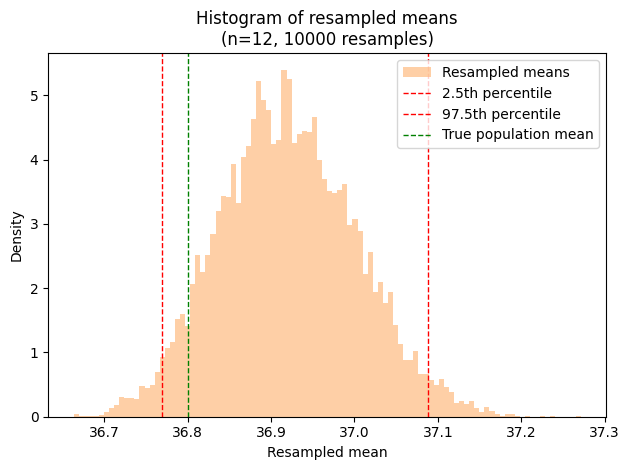
This resampling method offers a flexible alternative to traditional statistical methods, as it doesn’t require the assumption of a normal (Gaussian) or any specific distribution for the data. Here’s how it works:
Create numerous “pseudosamples”: repeatedly draw random samples (with replacement) from the original dataset, each with the same size as the original.
Calculate the statistic of interest: for each pseudosample, compute the mean (or any other parameter we’re interested in). This gives a large collection of estimates based on the original data.
Identify the percentiles: determine the 2.5th and 97.5th percentiles of this collection of estimates. This range, which contains 95% of the resampled means, serves as the 95% confidence interval (CI) for the population mean.
Remarkably, this resampling-based CI often aligns closely with the CI calculated using the conventional method that assumes a normal distribution. Extensive theoretical and simulation studies have validated this approach, leading some statisticians to advocate for its wider adoption.
The underlying principle behind resampling’s effectiveness is the Central Limit Theorem (again ;-). This theorem states that as we take more and more simple random samples from a population, the distribution of the sample means will approximate a normal distribution, regardless of the original population’s distribution. In other words, the average of the sample means will converge towards the true population mean as the number of samples increases. Learn more on bootstrap and computer-intensive methods in Wilcox (2010) and Manly and Navarro Alberto (2020).
# Set random seed for reproducibility
np.random.seed(111)
# Number of resamples
num_resamples = 10000
# Resampling and mean calculation
# !Make sure to choose exactly N elements randomly **with replacement**
# from the original N-data point set, e.g., size=12 for sample1 set
resampled_means = [
np.random.choice(
sample1,
size=len(sample1),
replace=True
).mean() for _ in range(num_resamples)]
# Calculate percentiles
percentile_2_5 = np.percentile(resampled_means, 2.5)
percentile_97_5 = np.percentile(resampled_means, 97.5)
# Plot histogram
# plt.figure(figsize=(4, 3))
plt.hist(
resampled_means,
bins=int(np.sqrt(len(resampled_means))), density=True, alpha=0.7,
label='Resampled means')
plt.axvline(
percentile_2_5,
color='r', linestyle='dashed', linewidth=1,
label='2.5th percentile')
plt.axvline(
percentile_97_5,
color='r', linestyle='dashed', linewidth=1,
label='97.5th percentile')
plt.axvline(
pop_mean,
color='g', linestyle='dashed', linewidth=1,
label='True population mean')
plt.xlabel('Resampled mean')
plt.ylabel('Density')
plt.title(f"Histogram of resampled means\n(n={len(sample1)}, {num_resamples} resamples)")
plt.legend()
plt.tight_layout();
# Print percentiles
print(f"2.5th percentile: {percentile_2_5:.3f}")
print(f"97.5th percentile: {percentile_97_5:.3f}")
2.5th percentile: 36.769
97.5th percentile: 37.088
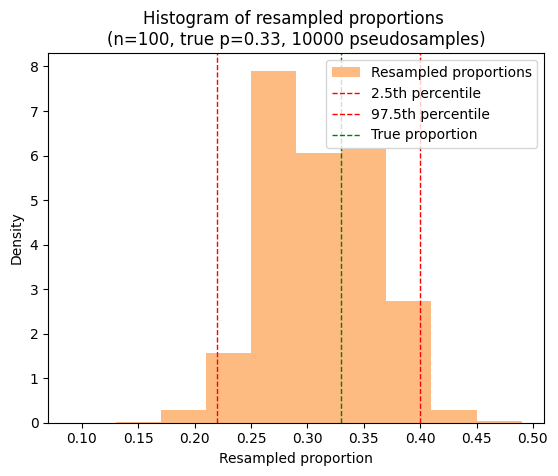
Confidence interval of a proportion via resampling#
The bootstrap method isn’t limited to means; we can apply it to proportions as well. Let’s revisit the voting scenario from an earlier chapter, where 33 out of 100 people voted a certain way. Our goal is to estimate the 95% confidence interval for the true proportion of the population who would vote this way, assuming a population proportion of 0.33 for our simulation.
# Original sample size and proportion of interest
n = 100
p = 0.33
# Number of resamples
num_resamples = 10000
# Set random seed for reproducibility
np.random.seed(42)
# Generate original sample
original_sample = np.random.binomial(1, p, n) # 1 for success, 0 for failure
# Resampling and proportion calculation
resampled_proportions = [
np.random.choice(
original_sample,
size=n,
replace=True)
.mean() for _ in range(num_resamples)]
# Calculate percentiles for 95% CI
percentile_2_5 = np.percentile(resampled_proportions, 2.5)
percentile_97_5 = np.percentile(resampled_proportions, 97.5)
# Plot histogram
# plt.figure(figsize=(4, 3))
plt.hist(
resampled_proportions,
density=True,
label='Resampled proportions')
plt.axvline(
percentile_2_5,
color='r', linestyle='dashed', linewidth=1,
label='2.5th percentile')
plt.axvline(
percentile_97_5,
color='r', linestyle='dashed', linewidth=1,
label='97.5th percentile')
plt.axvline(
p,
color='g', linestyle='dashed', linewidth=1,
label='True proportion')
plt.xlabel('Resampled proportion')
plt.ylabel('Density')
plt.title(f'Histogram of resampled proportions \
\n(n={n}, true p={p:.2f}, {num_resamples} pseudosamples)')
plt.legend();
# Print percentiles
print(f"95% bootstrap confidence interval for proportion: \
({percentile_2_5:.3f}, {percentile_97_5:.3f})")
# Calculate the 95% confidence interval for proportions using statsmodels.stats.proportion,
# now using binomial distrubution
ci_lower, ci_upper = sm.stats.proportion_confint(
count=33, nobs=n, alpha=0.05, method='binom_test')
print(f"The 95% confidence interval using statsmodels proportion_confint is \
({ci_lower:.3f}, {ci_upper:.3f})")
95% bootstrap confidence interval for proportion: (0.220, 0.400)
The 95% confidence interval using statsmodels proportion_confint is (0.244, 0.430)
Bootstrap with pingouin#
The bootstrap method doesn’t assume any particular distribution for the data, making it well-suited for analyzing complex or non-normal datasets. For example, the pingoui.compute_bootci function calculates bootstrapped confidence intervals of univariate and bivariate functions. Since version 1.7, SciPy also includes a built-in bootstrap function scipy.stats.bootstrap.
import pingouin as pg
# Calculate 95% percentile bootstrap confidence interval
ci = pg.compute_bootci(
sample1,
func='mean',
confidence=0.95,
method='cper', # Bias-corrected percentile method (default)
seed=111,
decimals=3,
n_boot=1000)
print(f"95% Percentile Bootstrap Confidence Interval: ({ci[0]:.3f}, {ci[1]:.3f})")
95% Percentile Bootstrap Confidence Interval: (36.768, 37.093)
The CI, SD and SEM#
As we saw in one previous figure, larger samples tend to yield more precise estimates of population statistics, reflected in their narrower distributions. The standard deviation of a statistic derived from a sample is called the standard error of that statistic. In the case of the sample mean, the standard error of the mean (SEM) or standard error (SE) is given by:
where \(\sigma\) is the (sample) standard deviation and \(n\) is the sample size. It’s important to remember that this calculation relies on the assumption that the sample standard deviation closely mirrors the population standard deviation, which is generally acceptable for samples of moderate or larger size. As the formula illustrates, the SEM is inversely proportional to the square root of the sample size. This confirms our intuitive understanding that larger samples lead to more precise estimates of the population mean, as evidenced by the smaller SEM.
We might also have noticed the term “standard error” or “standard error of the mean” appearing in previous calculations of the margin of error. Let’s take a closer look at the relationship between the confidence interval (CI) and the SEM, as they both play crucial roles in understanding the precision of our estimates.
A point estimate, such as the sample mean, gives us a single value to estimate a population parameter. However, estimates vary from sample to sample due to random sampling error. A confidence interval addresses this uncertainty by providing a range around the point estimate. This range is constructed to capture the true population parameter with a certain degree of confidence, often set at 95%. Wider intervals offer greater confidence in capturing the true parameter, but at the cost of reduced precision.
Recall that the SEM is a measure of how much the sample mean is expected to vary from sample to sample. It’s calculated as \(\text{SEM}=\frac{s}{\sqrt{n}}\). It quantifies the variability we expect to see in sample means due to random sampling error. A smaller SEM indicates that the sample mean is likely to be closer to the true population mean.
The margin of error in a confidence interval is directly related to the SEM. It’s calculated by multiplying the SEM by a critical value (either from the t-distribution or the z-distribution) that corresponds to our desired confidence level: \(W=t^* \times \text{SEM}\). The critical value depends on the chosen confidence level (e.g., 95% or 99%) and the degrees of freedom (if using the t-distribution).
Therefore, the confidence interval is essentially constructed by adding and subtracting the margin of error from the sample mean: \(\text{CI} = m \pm W\).
In essence, the confidence interval uses the SEM as a building block to create a range of plausible values for the population mean. The width of the confidence interval reflects the level of uncertainty in our estimate:
Narrow CI: smaller SEM, more precise estimate
Wide CI: larger SEM, less precise estimate
from scipy.stats import sem
# Calculate statistics
mean = np.mean(sample1)
sd = np.std(sample1, ddof=1) # Unbiased sample standard deviation
sample_sem = sem(sample1)
# Critical value for 95% CI
z_crit = norm.ppf(0.975) # Assuming normal distribution
W = z_crit * sample_sem # margin of error
# Calculate confidence interval
ci = (mean - W, mean + W)
# Plotting
plt.figure(figsize=(5,3))
# SD error bar
plt.errorbar(
1, mean,
yerr=sd,
fmt='o', capsize=5, lw=2,
label='Standard Deviation (SD)')
# SEM error bar
plt.errorbar(
2, mean,
yerr=sample_sem,
fmt='o', capsize=5, lw=2,
label='Standard Error of Mean (SEM)')
# 95% CI error bar
plt.errorbar(
3, mean,
yerr=W,
fmt='o', capsize=5, lw=2,
label='95% Confidence Interval (CI)')
# Add labels and title
plt.xticks([1, 2, 3], ['SD', 'SEM', '95% CI'])
plt.ylabel('Value')
plt.title('Comparison of SD, SEM, and 95% CI')
plt.legend()
sns.despine();
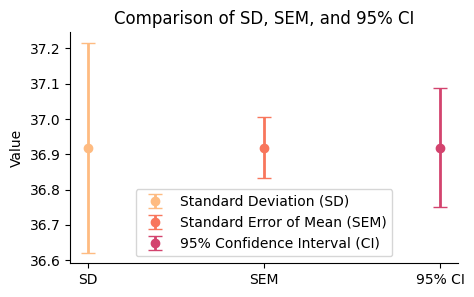
The error bar for SD is the longest, reflecting the variability of individual data points around the mean.
The SEM error bar is shorter than the SD, showing the reduced variability expected in sample means compared to individual data points.
The 95% CI error bar has a moderate width, indicating the range within which we are 95% confident that the true population mean lies.
The confidence interval of the standard deviation#
Confidence intervals are a versatile tool in statistics, applicable to a wide range of values calculated from sample data, not just the mean. Under common assumptions - a roughly Gaussian population distribution, a random and representative sample, independent observations, accurate data, and a meaningful outcome - a 95% CI allows us to be 95% confident that the calculated interval captures the true population parameter of interest, whether it’s the standard deviation, a proportion, or another statistic.
While the scipy.stats library doesn’t directly provide a function for calculating confidence intervals of standard deviation using the frequentist approach, it’s easy to implement it using the chi-squared distribution.
from scipy.stats import chi2
def std_dev_conf_interval(data, confidence=0.95):
"""
Calculate the confidence interval for population standard deviation
using the frequentist approach.
Args:
data (array-like): The sample data.
confidence (float): The desired confidence level (default: 0.95).
Returns:
tuple: The lower and upper bounds of the confidence interval.
"""
n = len(data)
# First calculate the unbiased (ddof=1) sample standard deviation
sample_std_dev = np.std(data, ddof=1)
alpha = 1 - confidence
# CI for the population SD is derived from the chi-squared distribution with DF=n-1
# Find the critical chi-squared values with PPF
chi2_lower = chi2.ppf(alpha / 2, df = n - 1)
chi2_upper = chi2.ppf(1 - alpha / 2, df = n - 1)
# Use sqrt((n - 1) * s**2 / crit_chi2)
lower_bound = np.sqrt((n - 1) * sample_std_dev**2 / chi2_upper)
upper_bound = np.sqrt((n - 1) * sample_std_dev**2 / chi2_lower)
return sample_std_dev, lower_bound, upper_bound
for sample in [sample1, sample2]:
n = len(sample)
print(f"SD and 5% confidence interval for standard deviation of sample with n={n} \
(chi²): \n\t {std_dev_conf_interval(sample)}")
SD and 5% confidence interval for standard deviation of sample with n=12 (chi²):
(0.2976964334156459, 0.21088670986063496, 0.5054522302512634)
SD and 5% confidence interval for standard deviation of sample with n=130 (chi²):
(0.38223178599879426, 0.34073809210625733, 0.4353236863653785)
We can also use the scipy.stats.bayes_mvs function to calculate Bayesian credible intervals for the standard deviation. This approach incorporates prior knowledge (or lack thereof) about the population parameters, which can be particularly useful when dealing with limited data. For sample size smaller than 1000, the function uses a generalized gamma distributed with shape parameters \(c=-2\) and \(a=(n-1)/2\).
for sample in [sample1, sample2]:
n = len(sample)
# Calculate Bayesian credible interval for standard deviation (alpha = 0.95 for 95% CI)
result = bayes_mvs(sample, alpha=0.95)
print(f"SD and 95% confidence interval for standard deviation of sample with n={n} \
(Bayes): \n\t{result[2]}")
SD and 95% confidence interval for standard deviation of sample with n=12 (Bayes):
Std_dev(statistic=0.32011752574920377, minmax=(0.21088670986063499, 0.5054522302512634))
SD and 95% confidence interval for standard deviation of sample with n=130 (Bayes):
Std_dev(statistic=0.3844721557624937, minmax=(0.34073809210625733, 0.4353236863653785))
Comparable values for the SD and 95% CI can be obtained from the “Confidence interval of a SD” calculator from GraphPad:
n |
SD |
lower |
upper |
|---|---|---|---|
12 |
0.29769643341564590 |
0.21088691265180180 |
0.50545211062390770 |
130 |
0.38223178599879420 |
0.34073641382308556 |
0.43532202087236800 |
While the bootstrap method is distribution-free and can be particularly useful for non-normal data, its results can vary depending on the size of the dataset. For larger datasets, the bootstrap confidence interval might closely align with the results obtained from frequentist or Bayesian approaches. However, for smaller datasets, the bootstrap confidence interval might exhibit greater variability and potentially deviate from the results of other methods due to the inherent randomness in resampling.
# Set random seed for reproducibility
np.random.seed(999)
# Number of resamples
num_resamples = 10000
fig, ax = plt.subplots(1, 2, figsize=(8,4))
for i, sample in enumerate([sample1, sample2]):
# Resampling and SD calculation
# !Make sure to choose exactly N elements randomly **with replacement**
# from the original N-data point set, e.g., size=12 for sample1 set
resampled_SDs = [
np.random.choice(
sample,
size=len(sample),
replace=True
).std(ddof=1) for _ in range(num_resamples)]
# Calculate mean and percentiles
percentile_2_5 = np.percentile(resampled_SDs, 2.5)
percentile_97_5 = np.percentile(resampled_SDs, 97.5)
mean_sd = np.mean(resampled_SDs)
# Plot histogram
ax[i].hist(
resampled_SDs,
bins=int(np.sqrt(len(resampled_SDs))),
density=True, alpha=0.7, color='darkslateblue',
label='Resampled standard deviations')
ax[i].axvline(
percentile_2_5,
color='r', linestyle='dashed', linewidth=1,
label='2.5th percentile')
ax[i].axvline(
percentile_97_5,
color='r', linestyle='dashed', linewidth=1,
label='97.5th percentile')
ax[i].axvline(
pop_sd,
color='g', linestyle='dashed', linewidth=1,
label='True population SD')
ax[i].set_xlabel('Resampled standard deviation')
ax[i].set_ylabel('Density')
ax[i].set_title(f"Histogram of resampled standard deviations\n(n=\
{len(sample)}, {num_resamples} replicates)")
ax[i].legend()
# Print percentiles
print(f"SD and 5% confidence interval for standard deviation of sample with \
n={n} (bootstrap): \n\t({mean_sd}, {percentile_2_5:.3f}, {percentile_97_5:.3f})")
plt.tight_layout();
SD and 5% confidence interval for standard deviation of sample with n=130 (bootstrap):
(0.28174628821656056, 0.178, 0.361)
SD and 5% confidence interval for standard deviation of sample with n=130 (bootstrap):
(0.3798135496552976, 0.335, 0.425)
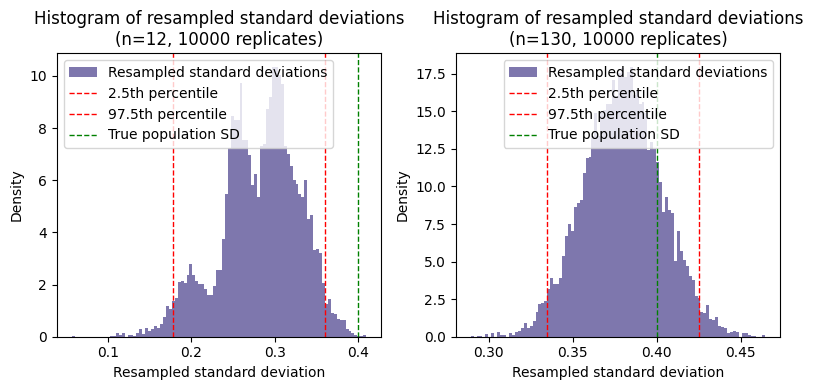
If the histogram of bootstrap replicates of the standard deviation appears multimodal (i.e., has multiple peaks), it suggests non-normality of the underlying population distribution from which the sample is drawn, sampling variability, especially if the sample size is small, and/or an actual underlying structure in the population. In the current example, we know that the original population is totally normal, therefore the sampling variability, with the small sample size, may affect the bootstrap process.
When faced with a multimodal bootstrap distribution of standard deviations, the traditional methods of constructing confidence intervals (e.g., using percentiles or assuming normality) might not be appropriate. Alternative methods, e.g., Bias-Corrected and Accelerated (BCa) bootstrap or the bootstrapped-t method, can be more suitable.
Conclusion#
In this chapter, we’ve explored the fundamental concept of confidence intervals and their essential role in statistical inference. We’ve learned that confidence intervals provide a range of plausible values for population parameters, like the mean, and quantify the uncertainty associated with those estimates.
We delved into the different methods for calculating confidence intervals, including the t-distribution for smaller samples and the z-distribution for larger ones. We also explored the Bayesian approach, which incorporates prior information, and the non-parametric bootstrap method, which is particularly useful for complex or non-normal data.
We’ve seen how confidence intervals can be visualized using plots, helping us grasp the relationship between sample size, variability, and precision. We also examined the close connection between confidence intervals and the standard error of the mean, a key measure of the uncertainty in our sample mean estimate.
By mastering confidence intervals, we’ve gained a powerful tool for analyzing data and drawing meaningful conclusions in the field of biostatistics. But confidence intervals are not just about numbers; they are about understanding the uncertainty inherent in estimation and making informed decisions based on that understanding.
Cheat sheet#
This cheat sheet provides a quick reference for essential code snippets used in this chapter.
t-distribution#
from scipy.stats import t
# Define the degrees of freedom (e.g., sample size - 1)
df = 27
# Define the t-distribution
t_distribution = t(df=df)
# Calculate mean, variance (and more), median and SD from the model
t_distribution.stats(moments='mv')
t_distribution.mean()
t_distribution.median()
t_distribution.std()
PDF Plot#
import numpy as np
import matplotlib.pyplot as plt
plt.plot(
# central 99.8% of the distribution
x:=np.linspace(
t_distribution.ppf(q=.001), # Percent Point Function
t_distribution.ppf(q=.999),
num=100),
t_distribution.pdf(x),
)
Critical t-values and z-values#
# Define the desired confidence level (e.g., 95%)
confidence_level = 0.95
# Calculate alpha (for two-tailed test)
alpha = 1 - confidence_level
# Calculate the critical t-value (two-tailed)
t_critical = t.ppf(q=(1 - alpha/2), df=df) # Percent Point Function
# Calculate critical bound t-values (direct method)
t_critical_lower = t.ppf(0.025, df=df) # Lower critical value at q = 0.025
t_critical_upper = t.ppf(0.975, df=df) # Upper critical value at q = 0.975
# Calculate the critical z-value (two-tailed)
from scipy.stats import norm
z_critical = norm.ppf(q=(1 - alpha/2))
Confidence interval#
# Population parameters
pop_mean = 36.8 # mean
pop_sd = 0.4 # standard deviation
# Generate toy sample derived from Normal distribution
n = 12 # sample size
sample = np.random.normal(
loc=pop_mean,
scale=pop_sd,
size=n)
sample_mean = 36.9184 # or use np.mean(sample)
sample_sd = 0.2977 # or use np.std(sample, ddof=1)
### Manual calculation of the CI
# Calculate the critical t-value
t_critical = t(df=n-1).ppf(q=1-alpha/2) # Percent Point Function
# Calculate the standard error of the mean
sem = sample_sd / np.sqrt(n) # or use scipy.stats.sem on data
#sem = pop_sd / np.sqrt(n) # if population SD is known
# Calculate margin of error
margin_error = t_critical * sem
#margin_error = z_critical * sem # large sample sizes and/or known population SD
# Calculate confidence intervals
(sample_mean - margin_error, sample_mean + margin_error)
### Computational calculation of the CI
# Frequentist - Small sample size and unknown population SD
import statsmodels.api as sm
sm.stats.DescrStatsW(sample).tconfint_mean(alpha=1-confidence_level)
# Equivalent to
t.interval(
confidence=confidence_level,
df=n - 1,
loc=sample_mean,
scale=sem) # here scale is SE, no SD as in normal distribution
# Frequentist - Large sample size and/or known population SD
norm.interval(
confidence=confidence_level,
loc=sample_mean,
scale=pop_sd) # or sample_sd
# Bayesian
from scipy.stats import bayes_mvs
# If n<1000, it uses the frequentist approach with the t-distribution
bayes_mvs(sample, alpha=0.95)[0][1] # extract `minmax` tuple from `mean`
# bayes_mvs(sample, alpha=0.95) # returns mean, var and SD with 95% credible intervals
Plot CI errorbar#
# 95% CI error bar
plt.errorbar(0, sample_mean, yerr=margin_error, fmt='o', capsize=4)
Bootstrap#
import pingouin as pg
# Calculate 95% percentile bootstrap confidence interval
pg.compute_bootci(
sample,
func='mean',
confidence=0.95,
method='cper', # Bias-corrected percentile method (default)
seed=111,
decimals=3,
n_boot=1000)
# Resampling and mean calculation
np.random.seed(111) # for reproducibility
num_replicates = 10000 # number of replicates
# !Make sure to choose exactly N elements randomly **with replacement**
# from the original N-data point set
resampled_means = [
np.random.choice(
sample,
size=len(sample),
replace=True
).mean() for _ in range(num_replicates)]
# Calculate percentiles
np.percentile(resampled_means, 2.5), np.percentile(resampled_means, 97.5)
# Plot the histogram
plt.hist(resampled_means, density=True, bins=int(np.sqrt(len(resampled_means))))
Session Information#
The output below details all packages and version necessary to reproduce the results in this report.
Show code cell source
!python --version
print("-------------")
# List of packages we want to check the version
packages = ['numpy', 'pandas', 'scipy', 'statsmodels', 'pingouin', 'matplotlib', 'seaborn']
# Initialize an empty list to store the versions
versions = []
# Loop over the packages
for package in packages:
# Get the version of the package
output = !pip show {package} | findstr "Version"
# If the output is not empty, get the version
if output:
version = output[0].split()[-1]
else:
version = 'Not installed'
# Append the version to the list
versions.append(version)
# Print the versions
for package, version in zip(packages, versions):
print(f'{package}: {version}')
Python 3.12.4
-------------
numpy: 1.26.4
pandas: 2.2.2
scipy: 1.13.1
statsmodels: 0.14.2
pingouin: 0.5.4
matplotlib: 3.9.0
seaborn: 0.13.2